Case Study
Snowflake Implementation for a Leading Consumer Lending Firm
The Need
A leading consumer lending organization, operating in multiple states within the contiguous United States, identified a challenge associated with having the capability to report across multiple areas of the business, in a timely and accurate manner. Several of the internal departments operated within their own data silos, constructed in several different ways. It was noted that it had become extremely cumbersome to aggregate and report on data enterprise wide. Each of the individual departments had dedicated analysts with different skill sets that were tasked with consolidating and presenting the data in the manner that was most comfortable. The organization operated on a “skeleton” IT crew with limited bandwidth to support all the individual processes.
Challenges identified by the business included:
- Limited data access
- Data Inconsistencies
- Reduced Collaboration
- Inefficient Data Retrieval
- Data Security Risks
- Compliance Concerns
- Manual / Cumbersome processes to generate required analytics
In response to these challenges, the client embarked on a journey to implement Snowflake, a cloud-based data warehousing platform, with the goal of centralizing and modernizing its data infrastructure, breaking down data silos, and enabling more efficient data management and analytics. This case study explores the motivations, planning, implementation, and outcomes of this strategic move to address their data challenges.
Implementation / Architecture
The Snowflake data architecture can be provisioned on any of the three major cloud providers (AWS, Microsoft Azure, Google Cloud Platform). The client already had a heavy presence within the Microsoft Azure cloud platform; therefore, it made logical sense to utilize and enhance the existing cloud storage layer in Blob Storage.
The Point-of-Sale system had itself been through an evolution over the past decade. It had been migrated from the legacy provider to a new one…. partially. While both systems were still being utilized in Day-to-Day operations, the organization decided to move all activity to a third Point-of-Sale system. All three POS systems were to be active for over 2 years until historical loans were cleared from the system, while ramping up the new. From a data harvesting perspective, the solution needed to have the flexibility to extract from all three systems on a nightly basis and made available for all data processing prior to the next business day.
Additional systems were identified that needed to be included in the overall architecture. These systems included Marketing, Risk, Underwriting, Payment Processing, and other ancillary systems that were deemed critical for the overall analytical solution. Overall, the client is leveraging over 10,000 artifacts to support the analytical solution.
The Microsoft Azure Data Factory service is being utilized for the data collection activities from all sources, including on-prem databases, Azure SQL Databases, multiple cloud solutions (including Salesforce), structured data (.txt, .csv files), and semi-structured data files in XML, JSON, HTML, and emails. All these files are loaded into an external stage in the Blob Storage account and ultimately ingested into the Snowflake database in the data storage layers identified in the “Data Storage” section below.
The data is transformed leveraging Snowflake services to provide a collection of “Blocks”, which consist of identified metrics for several different business areas within the organization. The illustration below depicts the data flow through the solution.

Data Sources
The client utilizes a variety of data sources that need to be consolidated into a single data layer for reporting. The sources consist of:
- Multiple On-Prem databases housing Point-of-Sale data that will eventually be decommissioned
- Multiple Azure SQL databases for Marketing content
- Salesforce
- Several systems that generate semi-structured content in the form of XML and JSON files
- Text and .csv files
Data Extraction
The Microsoft Azure Data Factory service is utilized for the data extraction component, and load into the Azure Blob Storage account. The files are loaded into Blob storage as a one for one from the source system, with the transformations being performed by the Snowflake services.
Data Storage
Data is stored in Blob Storage and ingested into Snowflake via streams to keep data updated as files are loaded into the storage account.
Snowflake allows for multi-tiers of data storage as depicted in the illustration below.
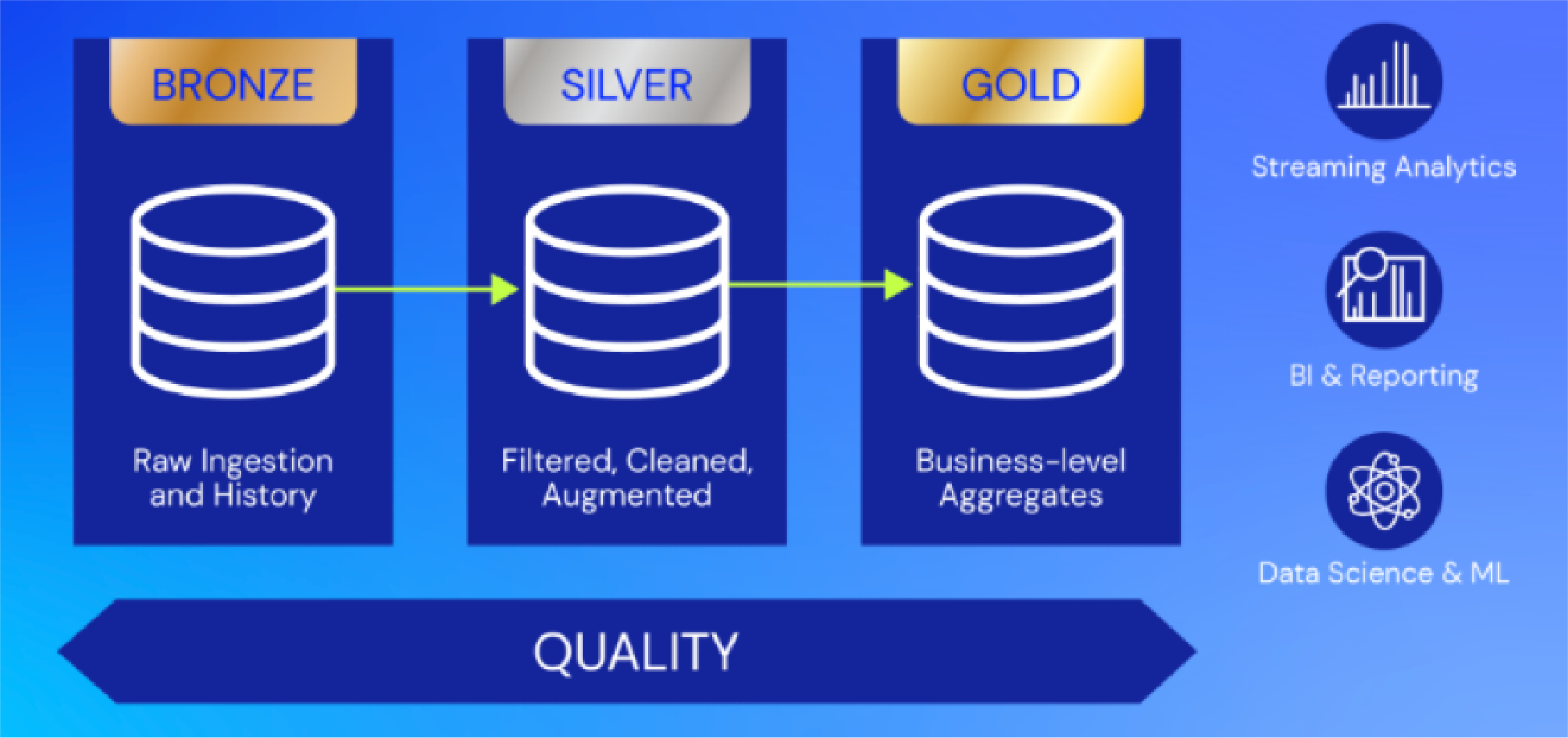
The Snowflake architecture was chosen to address the challenges being faced, including the following
- Scalability: Snowflake offers virtually unlimited scalability, allowing organizations to handle growing volumes of data without significant infrastructure investments. This scalability ensures that your data warehousing solution can grow with your business needs.
- Concurrent Access: Snowflake supports multiple users and concurrent queries, making it suitable for organizations with many users who need to access and analyze data simultaneously.
- Zero Maintenance: Snowflake manages the infrastructure, hardware provisioning, and software updates, reducing the burden on IT teams. This allows data professionals to focus on data analysis and not worry about infrastructure maintenance.
- Performance: Snowflake’s architecture, which separates storage from compute resources, enables efficient query performance. Users can scale compute resources up or down as needed to optimize query performance and reduce costs.
- Data Sharing: Snowflake allows organizations to securely share data with external partners, customers, or vendors without the need to move data between systems. This feature is valuable for data collaboration and monetization.
- Data Integration: Snowflake integrates with various data integration tools, making it easier to ingest data from various sources and integrate it into your data warehouse. This supports better data-driven decision-making by consolidating all relevant data in one place.
- Security: Snowflake offers robust security features, including data encryption at rest and in transit, role-based access control, and auditing. This helps organizations maintain data privacy and compliance with data security regulations.
Time Travel and Cloning: Snowflake provides features like Time Travel and cloning, allowing users to query historical data and create virtual copies of data for testing and development without impacting the original data.
Semi-Structured Data Support: Snowflake can handle semi-structured data formats like JSON, Parquet, and Avro, making it suitable for modern data processing needs.
Cost Efficiency: Snowflake’s pay-as-you-go pricing model means organizations only pay for the resources they use. It provides cost transparency, which can help manage data warehousing costs effectively.
Elasticity: Snowflake’s elastic compute resources can automatically adjust to match query demands, ensuring optimal performance during peak usage periods.
Global Availability: Snowflake is available on multiple cloud platforms, making it a suitable choice for organizations operating globally. It offers data replication across regions for high availability and disaster recovery.
Compliance: Snowflake complies with various data protection and privacy regulations, such as GDPR and HIPAA, which is essential for organizations handling sensitive data.
Start Your
Snowflake Journey
Ready to make the switch to Snowflake? Contact us to get started.